
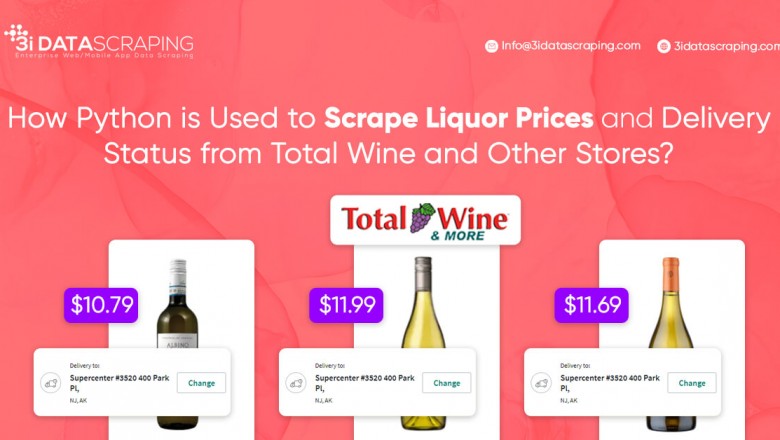
We will use Python 3 and other Python libraries to scrape Liquor prices and Delivery status from Total Wine and other stores.
Here are few data fields that will be extracted into an excel sheet:
- Name
- Price
- Size/Quantity
- Liquor Stock
- Delivery status
- URL
The data will be extracted in a CSV file as displayed below:
Installing the necessary package for executing Total Wine and Other Web Scrapers:
Initially, you will need to install Python 3 and use the below libraries:
- Python requests, requests and download the HTML script of the pages.
- Selectorlib, extracts data with the use of YAML files that we created from the web pages that we
download.
Installing them with pip3
pip3 install requests selectorlibThe Python Code
Create a file known as products.py and paste the below Python code into it.
from selectorlib import Extractor
import requests
import csv
e = Extractor.from_yaml_file('selectors.yml')
def scrape(url):
headers = {
'authority': 'www.totalwine.com',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.122 Safari/537.36',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'referer': 'https://www.totalwine.com/beer/united-states/c/001304',
'accept-language': 'en-US,en;q=0.9',
}
r = requests.get(url, headers=headers)
return e.extract(r.text, base_url=url)
with open("urls.txt",'r') as urllist, open('data.csv','w') as outfile:
writer = csv.DictWriter(outfile, fieldnames=["Name","Price","Size","InStock","DeliveryAvailable","URL"],quoting=csv.QUOTE_ALL)
writer.writeheader()
for url in urllist.read().splitlines():
data = scrape(url)
if data:
for r in data['Products']:
writer.writerow(r)
Below is the given is the result after executing the code.
- It analyzes a list of Total Wine and other URLs from a file known as urls.txt.
- It uses a selectorlib YAML files that will identify the information for Total Wine page and gets saved in a file known as selectors.yml.
- Extracts the information.
- The data gets saved in CSV format called data.csv.
Developing the YAML file-Selectors.yml
You will find that in the above code, we have used a file known as selectors.yml. This file will make the script very precise and easy. The reason behind creating this file is a web scraper tool known as Selectorlib.
Selectorlib is a visual and user-friendly tool for picking, marking up, and extracting information from web pages. The Selectorlib Web Scraper Chrome Extension allows you to mark information that you want to retrieve and then generate the CSS Selectors or XPaths you require.
Let’s see how we mention the fields for the information that we scrape by using Selectorlib chrome extension.
After creating the template, you can click on ‘Highlight’ to highlight and review all the selectors. Then, click on “Export” and download the YAML file and that file is known as selectors.yml file.
Have a look at the below template:
Products:
css: article.productCard__2nWxIKmi
multiple: true
type: Text
children:
Price:
css: span.price__1JvDDp_x
type: Text
Name:
css: 'h2.title__2RoYeYuO a'
type: Text
Size:
css: 'h2.title__2RoYeYuO span'
type: Text
InStock:
css: 'p:nth-of-type(1) span.message__IRMIwVd1'
type: Text
URL:
css: 'h2.title__2RoYeYuO a'
type: Link
DeliveryAvailable:
css: 'p:nth-of-type(2) span.message__IRMIwVd1'
type: Text
Executing Total Wine and More Scraper
You will now need to add the URL that you need to scrape into a text file known as urls.txt in a similar folder.
https://www.totalwine.com/spirits/scotch/single-malt/c/000887?viewall=true&pageSize=120&aty=0,0,0,0Then execute the scraper using the command:
python3 products.pyIssues That You Will Face Using This Code and Other Service Tools and Internet Copied Codes
Because programming degrades with age and websites evolve, basic script or one-time scripts will eventually fail.
Here are a few issues you might encounter if you are using this or any other unmaintained code or tool.
- If the website changes its design, for instance: the CSS selectors that we use for Price in the selectors.yaml file called price_1JvDDp_x will majorly change over time or even on regular days.
- The “location selection” for your “local” store will be based more on variables rather than your geolocated IP address and the website will ask you to choose the location. This does not get managed in simple code.
- The site will add new information points or edit the existing ones.
- The website will block the used User-Agent.
- The site will block the pattern to access this script will use.
- The website will block your IP address or all the IPs from your proxy.
All the above factors are the reasons why full-scraping service firms like 3i Data Scraping works better than self-service products and tools.
If you need any assistance with scraping liquor prices and delivery status from total wine then 3i Data Scraping knows your requirement, we will be glad to assist you.









